
Rising Academies was set up in 2014 to provide emergency education to children kept out of school by the Ebola Epidemic. Now they work with over 700 schools in Sierra Leone, Liberia, Ghana and Rwanda. Their mission is to create the best schools and the most powerful teaching and learning tools for the people that need them the most.
Laterite has partnered with Rising Academies to develop and pilot a custom AI-based Optical Character Recognition (OCR) pipeline using student assessment data from Sierra Leone and Ghana. The aim of this work is to accelerate the process of marking assessments and generate actionable data to support decision-making on student learning.
Harnessing data to improve decision-making
The data for this pilot comes from over 500 math assessments completed by grade 1, 2 and 4 students from 10 schools in Sierra Leone and Ghana, collected and scanned by Rising Academies staff. Using an AI-based OCR model, we then digitized the text, formatted the results into a dataset, and compared this with the data manually entered by the Rising Academies team. This enabled us to assess the accuracy of the tested models.
Challenge 1: Finding the right solution
The first challenge was to find a solution that can read the students’ handwriting with a high level of accuracy. The pilot process involved testing two solutions: Google Cloud’s Document AI and Amazon’s Textract. We initially chose Document AI because of its ability to tailor a custom OCR model to a specific area of the page.
After training and testing the model, we assessed its accuracy based on two metrics:
- Recall: What percentage of all data points can the model predict?
- Precision: How many of these are correctly predicted?
For our Document AI pilot, the model predicted 73% of the responses, and of these, it predicted 84% correctly. Combining these metrics, the model correctly predicted about 62% of data in the test set.
To improve the model’s accuracy we decided to test an alternative API. After exploring options such as PyTesseract, Watson Discovery and Azure AI Vision, we settled on Amazon’s Textract because it does not require any training data: it immediately scans and interprets all text on a given document, outputting a raw text file.
We tested the same assessments in Textract, using regular expressions in Python to format the individually scanned assessments into a usable dataset.
Textract had an overall performance of 86% of answers predicted correctly, substantially higher than the 62% from Document AI. But it’s still not a perfect score.
Challenge 2: What level of accuracy is acceptable for decision-making?
Despite extensive testing and adjustments, our model struggles to read unclear handwriting, smudges, and certain numbers. For example, a teacher might be able to interpret the number 5 in the image below, but Textract cannot accurately read these cases.
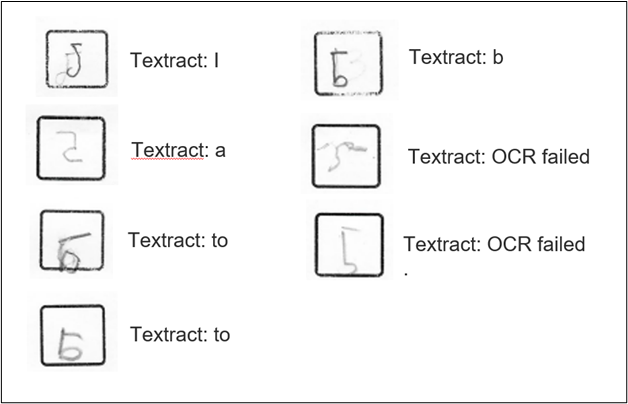
We can’t reasonably expect an OCR model to interpret these cases correctly 100% of the time. But this raises an important question: what accuracy level is needed in order to use this information for decision-making?
At an 86% accuracy level, the data might be useful for decision-making at a school or district level, where trends – and not individual scores – are of interest. At the classroom or student level, however, this model might not be good enough. It could penalize the students with non-standard handwriting, perhaps because they are still learning, or they were nervous, or in a hurry.
These are key considerations in determining next steps for the process. For example, one option would be to introduce human verification to the pipeline if text predictions fall below a certain confidence threshold (80% for example). An external enumerator or school staff member could then verify and correct only the less accurate predictions, rather than having to go through all assessment results.
What’s next?
In the next phase of our work, we’re exploring using large language models (LLMs) to turn digitized results into actionable feedback for teachers. Using LLMs, we can generate insights for teachers on various topics, such as student performance over time, differences by class and gender, and identifying which topics students are struggling with.
We can then link this to useful materials such as lesson plans, assessments, or other curriculum information. This will allow teachers to convert feedback on results into concrete next steps, such as revising certain materials on challenging topics. At the student level, this could mean creating pairs of students who struggle or excel in different areas to enhance peer-to-peer learning.
This blog was contributed by Oliver Budd, Senior Research Associate at Laterite Kenya. Read more about the potential for OCR to support decision-making in development contexts.